The Vibe-Eval Loop: TDD for Agents
The current state of the industry is that most people are building AI agents relying on vibes-only. This is great for quick POCs, but super hard to keep evolving past the initial demo stage. The biggest challenge is capturing all the edge cases people identify along the way, plus fixing them and proving that it works better after.
I'm not here, however, to preach against vibe-checking, quite the opposite. I think it's an essential tool, as only human perception can capture those nuances and little issues with the agent. The problem is that it doesn't scale, you can't be retesting manually forever on every tiny change, you are bound to miss something, or a lot.
The Vibe-Eval loop process then draws inspiration from Test Driven Development (TDD) to merge vibe debugging for agents with proper agent evaluation, by writing those specifications down into code as they happen, and making sure your test suite is reliable.
Scenario Tests
Scenario allows you to write tests for your agents using pytest or vitest, just like you would write UI end-to-end tests with playwright, but for agents, for example:
@pytest.mark.asyncio
async def test_vibe_coding():
template_path = clone_template()
def check_tool_calls(state: scenario.ScenarioState):
assert state.has_tool_call("read_file")
assert state.has_tool_call("update_file")
result = await scenario.run(
name="happy path",
description="""
User wants to create a new landing page for their dog walking startup.
""",
agents=[
Agent(template_path),
scenario.UserSimulatorAgent(),
scenario.JudgeAgent(
criteria=[
"agent reads the file before making changes",
"agent modified the index.css file",
"agent modified the Index.tsx file",
"agent created a comprehensive landing page",
"agent extended the landing page with a new section",
"agent DOES NOT say it can't read the file",
"agent DOES NOT produce incomplete code or is too lazy to finish",
],
),
],
script=[
scenario.user("hello, I want a landing page for my dog walking startup"),
scenario.agent(),
check_tool_calls,
scenario.user(),
scenario.agent(),
scenario.judge(),
]
)
print(f"\n-> Done, check the results at: {template_path}\n")
assert result.successIn this Scenario, we have a 2-step conversation between the simulated user and the vibe coding agent under test. On the scenario script, we include a hardcoded initial user message requesting a landing page. The rest of the simulation plays out by itself, including the second step where the user asks for a surprise new section. We don't explicitly code this request in the test, but we expect the agent to handle whatever comes its way.
We then have a simple assertion for tools in the middle, but the real power of this simulation are the several criteria being judged by the Judge agent.
How to define what criteria to test for?
You may wonder why the test includes something like "agent DOES NOT say it can't read the file." Where did that come from? It's a combination of two things:
- Behaviours that we expect to get before writing the prompt
- Issues we identify while vibe debugging the agent
As you will see on the next steps, writing down your expectations before you go an implement it, is a great way to "test the test", to make sure it fails for the right reasons, and it passes also for the right reasons. As you then identify more issues, you can add more criteria or create new scenarios to cover different aspects of the issue.
Each Scenario is a process, a cycle between you and your agent, where you refine the criteria until you are satisfied with its behaviour.
How I can trust this test?
"Isn't the Judge also non-deterministic? How can we trust this criteria and the Judge's decisions?"
This is a great question, this is why the TDD cycle is so important, you need to "test the test", until the scenario is reliable enough to trust and move forward.
So how do you do that?
When you spot an issue, don't fix it immediately. First, write a new scenario a new criterion to capture it. Then, run the tests, and watch it fail, just as it should. This way you know for sure that you can reproduce the issue, and that it's correctly caught by the test.
Only then should you fix the issue, and re-run the test to watch it pass. Now you've validated the the test and the fix. You can confidently refactor or change prompts later, knowing that if the issue ever reappears, the test will catch it.
You may still worry about non-determinism, but remember, each scenario is designed to test one thing, very specifically. Once it's works (especially with lower temperature settings), it will stay stable. Your prompts and agent architecture will keep evolving, but your tests, once solid, provide a dependable safety net.
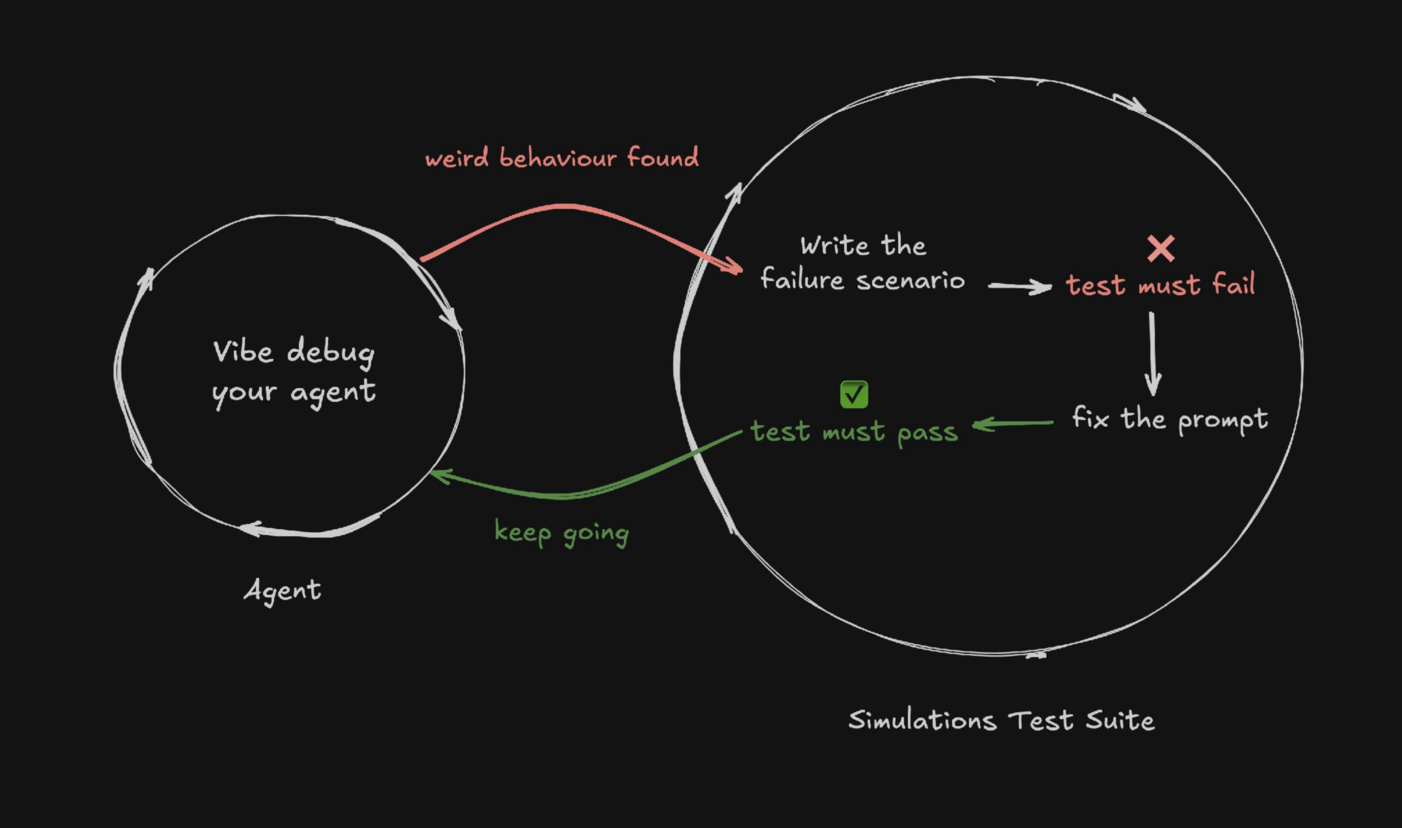
The Vibe-Eval Loop in a Nutshell
To develop AI agents with confidence:
- Play with your agent, explore edge cases, and vibe-debug it to find a weird behaviour
- Don't fix it yet, write a scenario to reproduce it first
- Run the test, watch it fail
- Implement the fix
- Run the test again, watch it pass
This will give you both the trust you need that your agent works, and freedom to refactor or iterate, knowing it won't break silently again.
Pro tip: This is also the best approach when developing new features or responding to bug reports. Don't jump into code or prompt changes: write a scenario first. You can even use Debug Mode to vibe-debug directly in the terminal.
Writing the test first has also the advantage of trying different fixes faster, and then being really done once you found one. There is no need to write a new test before merging it because the test has already been written upfront.
Testing a smaller piece?
If you see yourself testing just a specific part of your agent, where there seems to be too many tiny variations to cover, this probably shouldn't be an agent test but rather a dataset evaluation.
In cases like routing to the right agent, or retrieving the right chunks or detecting the right language, what you really need are accuracy metrics, and those are best measured with a dataset evaluation before integrating back into full agent scenarios.
Check out the Agent Testing Pyramid Guide, that shows how to combine different testing strategies, so you can really cover your agent quality from all angles.